专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
随着移动互联网和智能终端设备的普及,手写汉字OCR技术在智能手机输入法、银行票据处理、教育评估、历史文献数字化等领域的应用需求日益增长,推动了该技术的快速发展。手写汉字OCR技术是模式识别和人工智能领域最具挑战性的课题之一,与拉丁字母不同,汉字系统庞大复杂,常用汉字数量超过3000个,总字符集超过7万个,且具有相似字形多、结构复杂多变等特点。

手写汉字OCR技术面临多重独特挑战:
字符集规模庞大:国家标准GB18030-2005包含超过7万个汉字字符,远超英文26个字母的识别复杂度。
结构复杂性高:汉字由笔画、部首等部件组成,结构包括左右、上下、包围等多种类型,且相同部件在不同位置可能有不同形态。
书写变异性大:不同用户的书写风格差异显著,连笔、笔顺变化、笔画省略等现象普遍存在。
相似字区分困难:如"未-末"、"日-曰"、"人-入"等字形高度相似的字对,需要极其精细的特征提取才能区分。
动态与静态识别的差异:在线识别(书写轨迹已知)和离线识别(仅静态图像)面临不同的技术挑战。
在深度学习兴起前,传统手写汉字OCR技术主要采用以下技术路线:
二值化处理:将灰度图像转换为黑白二值图像;
去噪平滑:消除扫描或书写过程中产生的噪声;
倾斜校正:调整书写基线的倾斜角度;
归一化处理:统一字符大小和位置,常用方法包括线性归一化、基于矩的归一化等。
结构特征:提取笔画方向、交点、端点、环等拓扑特征;
统计特征:包括方向直方图(HOG)、Gabor滤波特征、梯度特征等;
变换域特征:如傅里叶描述子、小波变换特征等;
网格特征:将字符划分为若干区域,统计各区域特征。
模板匹配法:计算输入样本与模板的相似度;
统计分类器:包括k近邻(KNN)、支持向量机(SVM)等;
人工神经网络:如多层感知机(MLP)等浅层网络结构。
传统方法在受限环境下(如规范书写)可达到较好效果,但在处理自由手写体时性能明显下降。
中科逸视采用深度学习算法,显著提升了手写汉字OCR技术的性能,主要技术包括:
层次化特征学习:通过多层卷积自动学习从低级到高级的特征表示;
经典网络结构:如AlexNet、VGG、ResNet等在HCCR上的改进应用;
注意力机制增强:使网络能聚焦于字符的关键区分区域。
在线识别优势:利用LSTM、GRU等处理书写轨迹的时序信息;
多模态融合:结合图像空间信息和书写时序信息。
CNN-RNN混合模型:先用CNN提取空间特征,再用RNN建模上下文关系;
多任务学习框架:同时优化识别、书写质量评估等关联任务。
合成样本生成:通过形变、加噪等方式扩充训练数据;
预训练-微调范式:在大规模数据集上预训练,在目标领域微调。
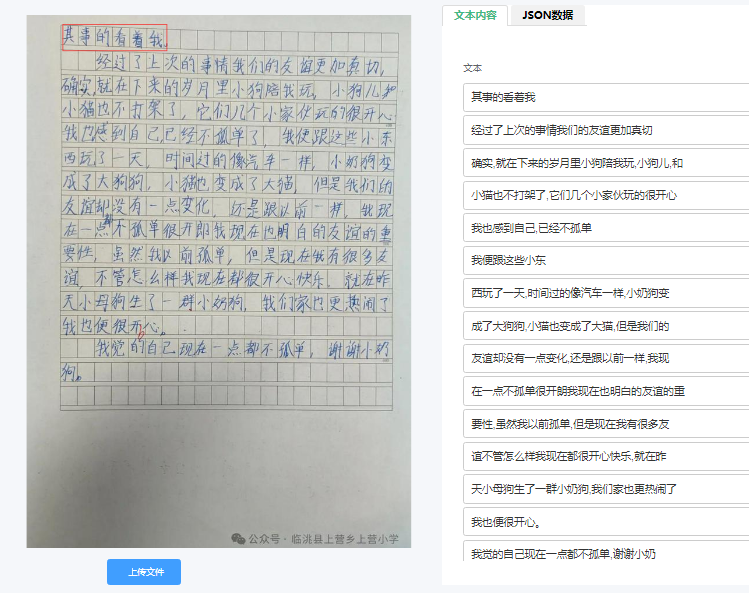
多风格兼容:可识别楷书、行书、草书等不同书写风格
抗干扰性强:有效处理纸张褶皱、墨水渗透、背景噪声等问题
多角度校正:自动矫正倾斜、旋转的文本图像
混合识别:同时处理印刷体和手写体混合文档
图像增强:自动调整亮度、对比度,强化笔画特征
版面分析:精确区分文本区域、表格、插图等不同版面元素
行分割与字切分:准确分离粘连字符,处理非常规排版
深度混合模型:结合CNN的空间特征提取与Transformer的全局关系建模
动态学习:支持用户书写习惯的持续学习与适应
多格式导出:支持TXT、DOCX、PDF、JSON等格式
结构化输出:自动识别并保留表格、列表等文档结构
批处理能力:支持大规模文档的自动化批量处理
移动设备输入:智能手机手写输入法
教育领域:作业批改、书写评估与纠正
金融行业:支票、票据的手写信息自动录入
文化保护:古籍文献的数字化与识别
智能办公:手写笔记的搜索与数字化管理
手写汉字OCR技术正在重塑人机交互的方式,它不仅是一项技术创新,更是文化传承的数字纽带。随着技术的不断进步,我们期待看到更多突破性的应用场景出现,让这一融合了人工智能与传统文化的技术,持续为各行业数字化转型赋能,为信息无障碍传递搭建更智慧的桥梁。未来,手写汉字识别技术将朝着更智能、更人性化、更包容多样性的方向发展,最终实现"任何人在任何地方以任何方式书写,都能被准确理解"的美好愿景。