专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2

俄语使用西里尔字母,部分字符形状相似(如 Ш(Sha)和 Щ(Shcha)、и(i)和 н(n)),容易导致识别错误。
大小写字母的差异(如 Т(T)和 т(t))可能影响识别精度。
俄语手写体连笔、变形较多(如 д(d)、г(g)的书写变体),传统OCR模型难以准确分割和识别。
不同人的书写风格差异大,缺乏统一标准。
俄语常与英语、数字、符号混排(如 “2024 г.”(2024年)、“E-mail: имя@example.com”),需要模型具备多语言混合识别能力。
俄语文档可能包含复杂排版(如诗歌、数学公式、表格),传统OCR难以保持原始结构。
古籍、旧报纸等历史文献的字体和印刷风格与现代不同,需额外训练数据优化识别。
俄文OCR技术的核心流程包括以下几个步骤:
图像预处理
去噪与增强:对扫描或拍摄的文档使用卷积操作进行噪声过滤和图像增强、对比度调整、二值化等处理,提高文本清晰度。
倾斜校正:检测并矫正文档的倾斜角度,确保文本行水平对齐。
版面分析:识别文本区域、表格、图片等,区分不同内容块。
字符检测与分割
行/词检测:通过投影分析或深度学习模型(如YOLO、EAST)定位文本行和单词。
字符分割:对俄语西里尔字母(如А, Б, В, Г)进行分割,为识别做准备。
字符识别
特征提取:使用卷积神经网络(CNN)提取字符的局部特征。
序列建模:结合循环神经网络(RNN)或Transformer模型(如CRNN、TrOCR)处理字符序列,提高识别准确率。
后处理与输出
拼写校正:利用俄语词典或语言模型(如BERT)修正识别错误。
格式还原:保留原始文档的排版(如段落、表格),输出为可编辑的TXT、PDF、Word等格式。
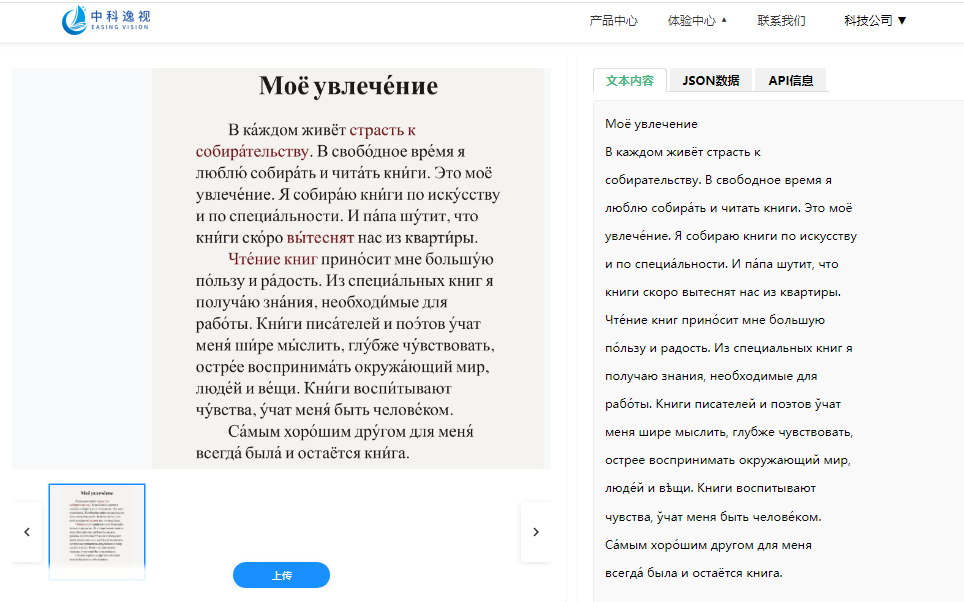
高精度识别:支持多种印刷字体(如Times New Roman、Arial),识别准确率可达95%以上。
多语言混合识别:可同时处理俄语、中文、数字及特殊符号的混合文本。
复杂背景适应:适用于扫描文档、照片、低分辨率图像等多种场景。
批量处理:支持大批量文档自动识别,提高企业级数据处理效率。
API集成:提供云端或本地API,便于嵌入企业系统、移动应用等。
企业办公自动化:
自动识别俄语合同、发票、财务报表,减少人工录入成本。
结合RPA(机器人流程自动化)实现智能文档分类与管理。
跨境贸易与物流:
快速处理俄语报关单、运单、订单,提升跨境电商运营效率。
教育科研:
数字化俄语教材、论文、古籍,便于检索和翻译。
辅助语言学习,如OCR扫描+即时翻译。
政府与公共服务:
自动识别护照、签证、身份证等证件信息,加快边检和政务流程。