专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
在数字化转型深入推进的当下,表格作为承载结构化数据的核心载体,广泛存在于金融票据、政务表单、医疗报告、档案文献等各类场景中。但纸质扫描件、手机拍摄图等非结构化格式的表格数据,长期依赖人工录入,效率低、误差高、成本大,成为数据价值挖掘的关键瓶颈。中科逸视(北京)科技有限公司深耕 AI 核心算法研发,自研高精度表格识别技术,内置版面分析与多语种文字识别能力,可自动提取结构化、半结构化表格的文字与布局信息,实现复杂表格内容精准解析与版面完整还原,为各行业数字化转型提供核心技术支撑。

技术原理:深度学习驱动的全流程智能解析
中科逸视表格识别技术以深度学习与计算机视觉为核心,融合图神经网络、Transformer 序列建模与语义理解技术,构建 “图像预处理 — 表格检测 — 结构解析 — 内容识别 — 结构化输出” 的端到端技术链路,核心逻辑模拟人类 “先看结构、再读内容” 的阅读思维,突破传统模板匹配方案对格式、场景的强依赖。
1. 图像预处理:多场景图像标准化净化
针对纸质扫描、手机拍摄、低质传真、逆光模糊等复杂来源的表格图像,通过多维度预处理算法消除干扰,保障输入质量:
2. 版面分析与表格检测:精准定位表格区域
内置自研版面分析引擎,结合改进的 YOLOv8 与 DETR 目标检测模型,在图文混排、多表格嵌套、无边框等复杂场景中,快速定位表格区域,区分表格与文本、图片等非表格内容,为后续解析锁定目标范围。
3. 表格结构解析:行列逻辑与布局还原
依托图神经网络与编码器 - 解码器架构,精准解析表格物理结构与逻辑结构:
4. 多语种文字识别:高精度内容提取
集成自研多语种 OCR 引擎,融合 Transformer 文字识别模型,支持中文、英文、数字、符号及小语种文字的高精度识别,字符识别准确率达 99.5% 以上。可精准提取单元格内文字、数字、手写备注等内容,兼顾印刷体与手写体识别,适配不同字体、字号、排版风格。
5. 结构化输出:数据与布局双重还原
最终输出可编辑、可分析的结构化数据(如 Excel、JSON、数据库格式),同时完整还原表格原始版面,保持行列对齐、单元格合并、边框样式等视觉特征,实现 “所见即所得” 的数字化重建,确保数据语义与布局一致性。
核心优势:全场景适配与高可靠解析
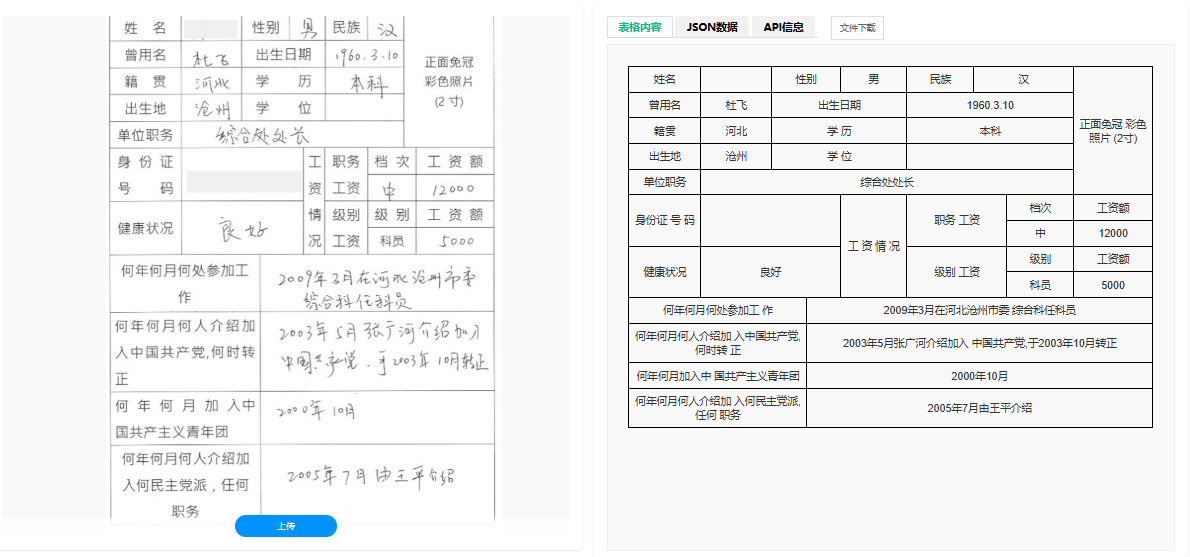
应用领域:赋能全行业表格数据智能化
表格识别技术已深度落地金融、政务、医疗、档案、物流等多个领域,助力企业与机构实现表格数据的自动化提取、结构化管理与智能化分析。
作为 AI 智能文档处理领域的核心技术,表格识别技术以深度学习为基石,融合版面分析、多语种 OCR 与结构推理能力,实现了多场景下表格文字的精准提取与布局的完整还原。从金融票据的智能审核到政务表单的高效处理,从医疗病历的结构化管理到档案文献的数字化盘活,该技术正持续为各行业数字化转型注入动力,推动非结构化表格数据向高价值结构化资产转化,助力企业与机构释放数据潜能,拥抱智能时代。