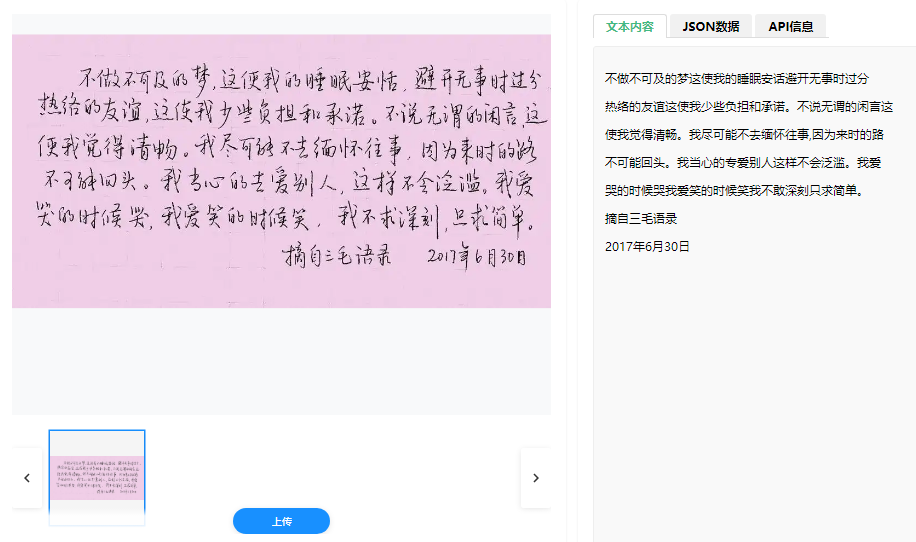
中文,以其数千年的文化积淀和独特的方块字结构闻名于世。在数字化浪潮席卷全球的今天,如何让机器精准“读懂”千差万别的手写汉字,成为人机交互的关键环节。中文手写体识别技术正扮演着这一重要角色,它不仅是人工智能领域的重大挑战,更是连接人与数字世界的智慧纽带。
技术核心:从像素到文字的智能解码
中文手写识别是一个复杂而精密的系统工程,融合了模式识别、图像处理与深度学习等多学科技术:
图像预处理:
-
二值化:将灰度/彩色图像转化为黑白两色,突出文字轮廓。
-
去噪滤波:消除扫描污渍、纸张纹理等干扰信息。
-
倾斜校正:自动调整书写歪斜的文本行。
-
归一化:将文字尺寸缩放至统一标准,减少尺度差异影响。
特征提取(传统方法):
-
结构特征:分析笔画方向、交点、端点、封闭区域(如“口”、“日”)等拓扑结构。
-
统计特征:计算像素分布、投影直方图(水平/垂直方向)、笔画密度等量化指标。
-
变换域特征:利用Gabor滤波、小波变换捕捉文字的纹理和方向信息。
深度学习主导的识别(当前主流):
-
卷积神经网络:自动学习文字图像的层级特征(边缘->部件->整体结构),是识别的基础骨干网络。
-
循环神经网络/Transformer:处理序列数据(如连续手写行),建模字符间的上下文关系,提升连续书写的识别准确率。
-
端到端训练:输入原始图像,直接输出识别文字序列,大幅简化流程并提升性能。
后处理与纠错:
-
语言模型:利用大规模中文语料库训练的语言模型,根据上下文语义纠正可能的识别错误(如将“未”纠正为“来”)。
-
词典约束:结合特定应用场景的词典,提高特定领域词汇的识别准确率。
技术难点:破解中文手写的“千变万化”
中文手写识别的难度远超西方拼音文字,主要挑战在于:
1.字符集庞大:
-
常用汉字数千(GB2312: 6763字,Unicode: 超9万字),远超英文26字母,模型需区分极多相似类别。
2.结构极其复杂:
-
汉字由笔画、部首以多种方式(左右、上下、包围、嵌套)组合而成,结构复杂度高(如“矗”、“龘”)。
3.书写风格差异巨大:
-
字体多样:楷书、行书、草书等书写风格迥异,同一字写法千差万别。
-
笔画变形与连笔 行书、草书笔画简化、粘连、省略严重,难以拆分(如“的”字草书)。
-
个人书写习惯: 笔画顺序、长短、倾斜角度等因人而异。
4.相似字区分困难:
-
大量形近字(如“未-末”、“土-士”、“日-曰”)在潦草书写下极易混淆。
5.版面分析与切分:
-
自由书写时字间距不均、行歪斜、字符重叠,需精准定位和分割单个文字。
功能特点:打造流畅自然的交互体验
中科逸视中文手写识别系统具备以下核心能力:
-
高精度识别:在约束书写条件下,对工整手写体的识别率可达98%以上;对自由书写具备相当鲁棒性。
-
多字体风格适应:可较好识别楷书、行书乃至部分草书。
-
连续手写识别:无需逐字书写,支持整句、整行连续输入,自动切分文字。
-
多平台支持:可集成于手机、平板、手写板、智能终端、服务器等。
应用场景:赋能千行百业的数字化转型
中文手写识别技术已深度融入日常生活与产业运作:
教育领域:
-
智能批改:自动识别批阅学生手写作业、试卷(尤其是客观题)。
-
电子笔记:将手写课堂笔记、板书实时转换为可编辑文本。
-
手写作文识别与辅助评分。
金融与政务:
-
银行表单处理:自动识别录入开户申请表、支票、汇款单等手写信息。
-
政务窗口:快速录入各类申请表格、证明材料中的手写内容。
医疗健康:
-
识别医生手写处方、病历、检查单,辅助电子化归档与信息提取。
文档数字化与归档:
-
图书馆、档案馆将历史手稿、文献、档案数字化并建立可检索数据库。
考古与文献研究:
未来趋势与挑战
中文手写识别技术虽已成熟,仍在持续进化:
-
极端自由书写与草书识别:提升对极度潦草、个性化书写的理解能力仍是核心挑战。
-
小样本/零样本学习:解决罕见字、生僻字或新书写风格的识别问题。
-
多模态融合:结合语义理解、语音等上下文信息提升识别效果。
-
无监督/自监督学习:减少对海量精细标注数据的依赖。
-
边缘计算与轻量化:在资源受限的设备(如IoT设备)上部署高性能识别模型。
-
伪造笔迹检测:结合识别技术鉴别手写真伪,应用于安全领域。
中文手写体识别技术,是人工智能在感知与认知领域的一项重大成就。它打破了键盘输入的局限,尊重并延续了人类悠久的书写传统,在数字化洪流中为文化传承架起桥梁。随着深度学习等技术的不断突破,未来的手写识别将更加精准、自然、普适,进一步消除人机交互的壁垒,为智慧教育、高效政务、便捷金融等场景提供强大支撑。当机器真正“读懂”每一笔饱含个性的书写,人与数字世界的连接也将更加温暖而紧密。