专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
在信息爆炸的时代,我们每天面对海量的文档数据——企业报告、学术论文、法律文书、医疗记录等。这些文档中蕴含着宝贵的结构化信息,但如何高效地从中提取出所需数据,却是一个巨大的挑战。文档信息抽取技术正是解决这一难题的关键,它犹如一位不知疲倦的数据矿工,能够从非结构化的文档中挖掘出结构化的知识宝藏,为信息的高效利用和分析提供了有力支持。

工作原理:从原始文档到结构化数据
文档信息抽取技术的核心工作流程可分为四个关键阶段:
文档预处理与解析是第一步:系统首先接收各种格式的输入文档(PDF、Word、图像等),通过OCR(光学字符识别)技术将扫描文档转换为机器可读的文本,同时保留文档的布局和格式信息。这一步骤确保了无论是数字原生文档还是纸质扫描件,都能被统一处理。
文档结构与布局分析紧随其后:系统识别文档的物理和逻辑结构——区分标题、段落、表格、列表等元素,理解它们的空间关系和层次结构。深度学习模型在此阶段发挥着重要作用,能够识别复杂的表格结构和多栏布局。
关键信息定位与提取是核心环节:基于自然语言处理(NLP)技术,系统识别并提取预定义的实体和信息片段。传统方法依赖规则和模板,而现代方法则采用序列标注模型(如BiLSTM-CRF)和预训练语言模型(如BERT),通过命名实体识别(NER)技术精准定位目标信息。
后处理与结构化输出是最后一步:提取的信息经过验证、归一化和关联,最终转化为结构化的数据格式(如JSON、XML或直接存入数据库),为下游应用提供可直接使用的标准化数据。
技术难点:跨越准确性与复杂性的鸿沟
文档信息抽取面临多重挑战:
布局多样性是首要难题:不同文档有着千变万化的版式设计——多栏布局、复杂表格、嵌套结构等,要求系统具备强大的布局理解和适应能力。
文档格式多样性:不同的文档格式(如PDF、Word、HTML、Excel 等)具有不同的结构和布局,而且同一格式的文档也可能存在不同的排版方式。例如,PDF 文档可能包含复杂的表格、图片、公式等元素,Word 文档可能存在不同的字体、字号、段落格式等。这使得文档预处理变得困难,需要针对不同的文档格式设计不同的处理方法。
语义理解深度决定提取质量:同一种信息可能以多种语言形式表达(如日期可写为"2023年12月1日"或"01/12/23"),需要系统理解语言背后的语义而非仅仅模式匹配。
领域专业性:不同领域的文档具有不同的专业术语和知识体系,如医疗、法律、金融等领域。例如,医疗文档中包含大量的医学术语,如"高血压"" 糖尿病 ""心电图" 等;法律文档中包含大量的法律术语,如 "合同"" 侵权 ""诉讼" 等。这要求信息抽取模型具有较强的领域适应性,能够学习和理解不同领域的专业知识。
处理精度与效率的平衡是工程实现的挑战:大规模文档处理需要算法既保持高精度,又具备合理的处理速度,这对系统架构设计提出了更高要求。
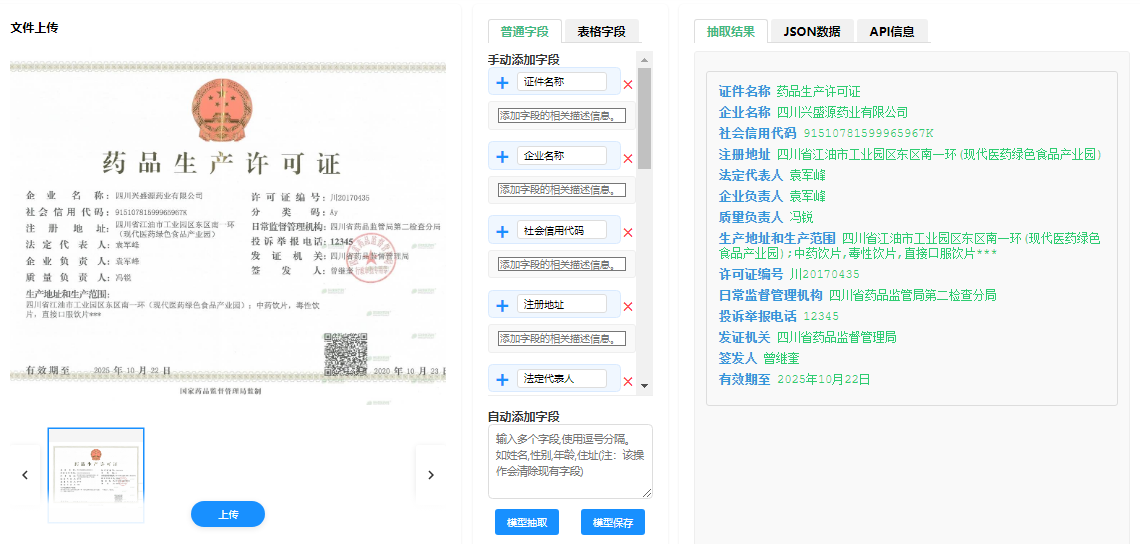
功能特点:智能抽取的多维优势
现代文档信息抽取系统展现出多方面优势:
高精度与召回率得益于深度学习技术的应用:现代系统在多数场景下能达到90%以上的抽取准确率,大幅降低人工校验成本。
多文档格式支持扩展了应用范围:无论是结构化程度高的PDF/Word,还是非结构化的扫描图像,系统都能处理,提供统一的数据输出接口。
自适应与可定制满足个性化需求:用户可以通过提供样本数据训练定制化模型,使系统适应特定领域和文档类型的抽取需求。
实时处理能力支持流式数据处理:现代系统能够实现近实时的文档处理,满足对时效性要求高的应用场景。
应用场景:赋能千行百业的智能转型
文档信息抽取技术正在各行各业发挥重要作用:
金融与保险领域应用广泛:系统可自动处理贷款申请、保险合同、财务报告等文档,提取关键数据点,加速业务流程,降低人为错误。例如,保险公司使用该技术自动处理索赔表单,将处理时间从小时级缩短到分钟级。
医疗健康行业受益显著:电子病历、检验报告、医疗影像报告中的结构化信息被自动提取,支持临床决策和医学研究,同时保障数据标准化和互操作性。
法律与合规部门效率提升:法律合同、合规文档中的条款、日期、义务等信息被自动抽取和分类,大大减轻律师和合规人员的工作负担。
政府与公共服务转型加速:政府部门利用该技术处理各类申请表单、档案材料,实现政务流程自动化,提升公共服务效率和透明度。
学术研究与教育领域创新应用:研究人员从大量学术文献中自动提取实验数据、研究方法等信息,加速知识发现和文献综述过程。
从信息海洋到知识图谱,文档信息抽取技术正帮助我们重新发现和利用那些沉睡在文档中的宝贵信息,开启智能信息处理的新纪元。文档信息抽取技术作为连接非结构化文档与结构化数据的桥梁,正在成为企业数字化转型的核心驱动力之一。它不仅是技术进步的体现,更是人类应对信息过载挑战的重要工具,将持续赋能智能时代的知识管理和决策支持。