解码古老的语言:基于深度学习的阿拉伯文字识别技术
- 栏目:公司新闻 时间:2025-09-23 20:13 分享新闻到:
<返回列表
在数字化浪潮席卷全球的今天,如何让古老而复杂的文字被机器准确理解和处理,是一项关键挑战。阿拉伯文,作为世界上使用最广泛的文字系统之一,以其独特的右向书写、字母形变和连写规则,成为了光学字符识别(OCR)领域的一座高峰。中科逸视基于深度学习的技术成功攻克了诸多传统方法难以解决的难题,极大地推动了阿拉伯文识别的发展。

实现过程:从图像到文本的深度学习流水线
中科逸视基于深度学习的阿拉伯文识别系统流程如下:
1. 数据预处理(Preprocessing)
图像规范化:将输入图像转换为灰度图,进行二值化、去噪、纠偏(矫正倾斜)等操作,为后续分析提供干净的输入。
行/词分割:虽然不分割字符,但通常需要先利用投影分析等方法将文本段落切割成独立的文本行(Text Lines)的图像区域。
2. 特征提取(Feature Extraction)
使用卷积神经网络(CNN)(如VGG、ResNet)作为骨干网络。CNN充当一个强大的“视觉特征提取器”,从输入的文本行图像中逐层提取出从边缘、笔画到更复杂的字符部件的特征图(Feature Maps)。
3. 序列建模(Sequence Modeling)
将CNN提取的特征图视为一个特征序列,输入到循环神经网络(RNN)(如LSTM、GRU)中。RNN的优势在于处理序列数据,它能够从左到右(尽管文字是右向,但模型通常按此顺序读取特征)扫描特征序列,并利用历史信息来理解上下文,从而解决因连写导致的字符歧义问题。
4. 转录(Transcription)
这是将RNN输出的序列解码为最终文本的过程。最主流的方法是Connectionist Temporal Classification (CTC) 损失函数。
CTC的优势:它允许模型无需确切的字符位置标注,直接输出一个字符序列。它能自动处理输入(图像特征)与输出(文本)之间的长度对齐问题,并巧妙地将RNN输出的重复字符和空白符(blank)合并,生成最终的预测结果(例如,将“--ss-aa--mm--pp--ll-ee”合并为“sample”)。这对于处理连写的阿拉伯文至关重要。
5. 训练与优化
使用大量标注好的阿拉伯文文本行图像(图像-文本对)来训练整个网络(CNN+RNN+CTC)。通过反向传播和梯度下降算法,不断调整网络参数,最小化CTC损失函数,使得模型的预测文本越来越接近真实标签。
6. 后处理(Post-processing)
利用语言模型(Language Model) 或词典对原始识别结果进行校正。例如,模型可能将某个字符误识别为形态相似的另一个,通过检查这个词在语言中的常见程度或是否存在于词典中,可以自动纠正这类错误,进一步提升准确率。
功能特点:为何深度学习是 game-changer?
与传统基于手工特征和模板匹配的OCR技术相比,中科逸视基于深度学习的阿拉伯文识别系统展现出革命性的优势:
极高的准确率与鲁棒性:深度学习模型,特别是卷积神经网络(CNN),能够自动从海量数据中学习阿拉伯文字符的深层、抽象特征,对字体变化、轻微模糊、光照不均、背景干扰等具有极强的容忍度。
端到端学习:现代架构(如CRNN)实现了从原始图像到文本序列的端到端训练,无需繁琐的人工特征工程和字符分割步骤,简化了流程,提高了整体性能。
上下文理解能力:循环神经网络(RNN)和注意力机制(Attention)的引入,使模型能够利用阿拉伯文词汇的上下文信息,准确推断因连写而变得模糊的字符身份,特别是在判断字母中间形、尾形时至关重要。
大规模应用能力:一旦模型训练完成,它可以被高效部署,处理海量的文档图像,为图书馆古籍数字化、政府公文处理、移动应用(如实时翻译)等场景提供核心技术支持。
核心难点:阿拉伯文识别的独特挑战
在将深度学习应用于阿拉伯文时,我们必须直面其文字系统固有的复杂性:
字母的形态变化(Contextual Forms):这是最核心的难点。一个阿拉伯字母根据其在词首、词中、词尾或独立出现,形态会发生显著变化(例如: → ‹ , , , ›)。模型必须学会这28个基本字母的上百种变体,并将其正确映射回基本字母。
复杂的连写规则(Cursive Script):阿拉伯文从右向左书写,且词语内的字母几乎总是连写的。这导致字符分割极其困难,传统OCR先分割再识别的思路在此完全行不通,必须采用以识别促分割的策略。
点缀符号(Diacritics)的干扰与价值:阿拉伯文包含丰富的点(dots)和附加符号(如ﹷﹹﹻﹽ等),这些符号是区分不同字母的关键(如: , , , )。但它们体积小、易在图像中丢失或模糊,给识别带来了巨大挑战。同时,这些符号还表示元音,在高级应用中(如语音合成)不可或缺。
右向书写(Right-to-Left Direction):这与大多数其他文字的方向相反,需要在设计模型输出序列和处理流程时进行特殊考虑。
字体多样性与古籍难度:印刷体和手写体风格千差万别,尤其是历史文献中可能存在褪色、污渍、复杂装饰背景等,对模型的泛化能力提出了极高要求。
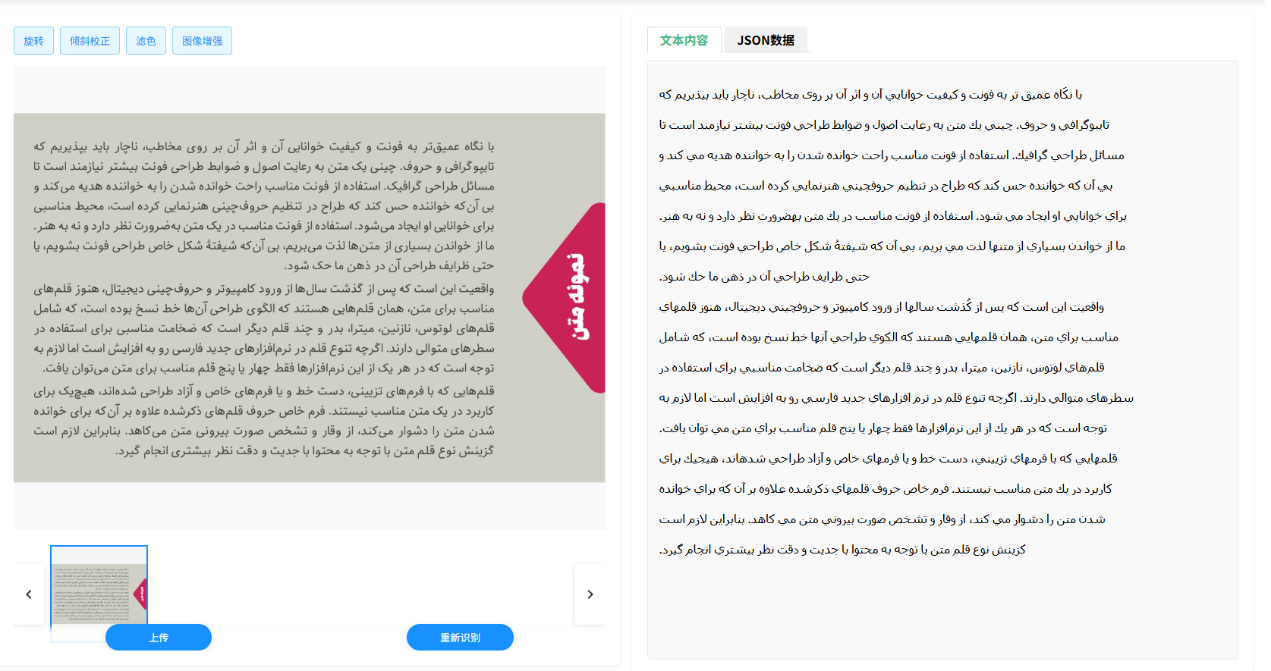
应用场景:从古老典籍到现代生活
中科逸视阿拉伯文识别技术正在多个领域焕发生机:
古籍文献数字化:自动将海量的阿拉伯语历史手稿、宗教典籍转换为可搜索、可编辑的电子文本,助力文化遗产的保存与研究。
智能办公与教育:开发阿拉伯文OCR软件,用于快速识别扫描的PDF、书籍和表格,提高办公效率。在教育领域,可用于作业批改、发音辅助学习等。
金融与商业:银行支票的自动处理、发票信息提取、商品包装上的文字识别等。
无障碍技术:为视障人士开发“拍照-朗读”应用,帮助他们阅读药品说明书、餐厅菜单等。
移动互联网应用:实时翻译软件(如Google Translate的实时相机功能)、社交媒体中的图片内容搜索等。
中科逸视基于深度学习的阿拉伯文识别技术,正以前所未有的精度和智能化水平,打破人与古老文字之间的数字壁垒。尽管在极端手写体、复杂背景干扰等方面仍有提升空间,但随着Transformer等新架构的引入和无监督学习技术的发展,未来机器对阿拉伯文的理解必将更加深入和自然,进一步推动阿拉伯世界与全球数字经济的深度融合。
更多阅读
-
- 公司新闻 2026-05-20
- 在数字化转型的浪潮中,不动产登记作为确认物权、保障交易安全的核心环节,正面临着海量...
查看全文
-
- 公司新闻 2026-04-23
- 在智慧交通与数字化政务的浪潮中,车辆证件的高效处理已成为提升行业效率的关键环节。中...
查看全文
-
- 公司新闻 2026-04-22
- 在数字化转型浪潮中,如何高效、准确地处理海量纸质证件信息,已成为各行各业提升效率的...
查看全文
返回全部新闻