专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2

德语OCR技术通过计算机视觉(CV)和自然语言处理(NLP)的结合,将图像中的德语文本转换为可编辑的数字化内容。其工作流程可分为以下几个阶段:
去噪与增强:采用自适应二值化、边缘检测等技术,优化低质量扫描文档。
版面分析:识别文本区域、表格、图片等,确保德语的复杂版式(如多栏排版)被正确解析
字符分割:针对德语长单词和连字符(如"Donaudampfschifffahrtsgesellschaft")进行精准切分
深度学习模型:采用CNN(卷积神经网络)+ LSTM(长短期记忆网络)架构,识别德语特有的字母(ß, ü, ö, ä)和复合词
多字体支持:训练模型识别现代标准字体(如Arial, Times New Roman)及历史字体(如Fraktur)
上下文优化:结合德语语法规则,纠正OCR识别错误(如名词首字母大写规则)
拼写检查:利用德语词典和NLP模型(如BERT)自动修正识别错误。
结构化输出:支持TXT、PDF、Word等格式,保留原始文档的排版、表格和脚注
目前德语OCR技术的主要难点集中在以下几个方面:
复杂语言特性:
超长复合词(如"Donaudampfschifffahrtsgesellschaft")容易识别不全或错误分割
特殊字符(ä, ö, ü, ß)在低质量图像中易被误识别
名词首字母大写的语法规则增加了识别复杂度
字体多样性:
现代标准字体与历史字体(如Fraktur哥特体)差异巨大
手写体(如Sütterlin)连笔严重,字符边界模糊
版式复杂性:
多栏排版、脚注、表格等复杂版式影响文本顺序识别
老旧文档的褪色、污渍会降低识别准确率
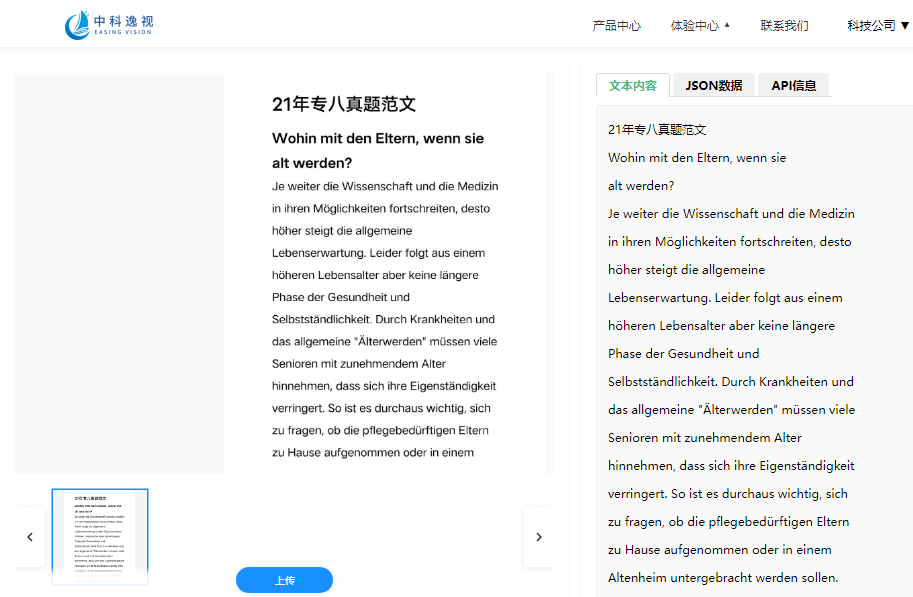
德语OCR技术的功能特点
• 多字体兼容:可识别包括Antiqua、Fraktur在内的12种德语历史字体
• 高精度识别:对印刷体识别准确率>99%
• 智能分词:准确处理德语中平均19个字母的超长复合词
• 格式保留:完整还原原文的段落结构、表格及特殊符号
• 支持中德文字混排识别
德语OCR技术的应用场景财务与合同管理:自动提取德语发票中的金额、日期、供应商信息,减少人工录入错误
客户服务:扫描德语信件或邮件,自动分类并生成可搜索数据库。
古籍电子化:将16-19世纪的德语书籍转换为可检索的电子文本
论文检索:帮助研究人员快速从扫描版PDF中提取关键内容
司法档案管理:自动识别法院判决书、法律条文,提高检索效率
历史档案保护:数字化二战前后的德语政府文件,便于历史研究
德语OCR技术正在重塑信息处理方式,使其在商业、学术、法律和工业领域发挥重要作用。随着AI技术的进步,未来的OCR系统将更加智能化,成为跨语言、跨媒介数据处理的核心工具。