专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
在政务服务数字化转型的浪潮中,政务服务中心作为服务群众和企业的最前沿,每日需处理海量各类申请表单,涵盖企业开办、社保参保、不动产登记、民生福利申领等多个领域。这些申请表单形式多样,既有标准化的结构化表格,也有因业务特性衍生的半结构化表格,传统人工录入与处理模式面临效率低下、误差率高、信息流转不畅等诸多痛点,已成为制约政务服务效能提升的关键瓶颈。
中科逸视(北京)科技有限公司依托其在高精度OCR与大模型融合技术领域的深厚积累,推出智能文档抽取系统,将文档抽取技术创造性地引入政务大厅智能表单处理场景,以“大模型+高精度OCR”双轮驱动,实现从“看得见”到“读得懂”再到“抽得出”的智能跃迁,为政务服务的智能化升级提供了全新路径。
技术原理:OCR与大模型的深度融合
中科逸视文档抽取系统的核心技术建立在“高精度OCR引擎”与“领域微调大模型”深度融合的基础之上,两者的协同构成了一套面向复杂版式文件的智能文档理解系统,实现了从图像到结构化信息的完整转换。
1. 高精度OCR引擎:构建文本基础
文档抽取系统首先通过高精度OCR引擎完成从图像到可编辑文本的基础转化。该系统采用基于CNN-Transformer混合架构的先进OCR模型,在图像预处理阶段集成了自适应二值化、透视校正、去噪增强等多种算法,可有效应对政务表单采集过程中常见的光照不均、倾斜、印章遮挡等问题。
在识别环节,系统利用基于Transformer的文本检测与识别模型,实现对中文、数字、符号等多类型字符的高精度OCR识别,印刷体识别准确率高达99.5%以上。尤为重要的是,OCR模块不仅输出纯文本,还保留了空间布局与视觉语义线索,包括文本坐标、字体、行高、段落关系等元信息,为后续大模型提供了具备上下文感知能力的丰富输入。
2. 大模型微调训练:实现语义理解
单纯OCR输出的文本是离散且缺乏结构关联的。文档抽取系统引入大语言模型作为语义理解与信息抽取的核心引擎,并通过微调训练使其适配政务表单处理场景。微调过程包含两大关键步骤:
在推理阶段,模型并非简单地在文本中匹配关键词,而是基于对文档语义的整体理解,准确定位并抽取对应字段的取值。无论“统一社会信用代码”位于营业执照的左上角、右上角还是以表格形式呈现,模型均能根据语义特征进行精准识别。
3. 融合机制:多层次协同校验
OCR与大模型的融合并非简单的流水线串联,而是存在多层次的交互与校验。当OCR对某区域识别置信度较低时,系统将该信息传递至大模型,模型可结合上下文语义进行推测与纠错。例如,OCR将“有限责任公司”误识为“有限贡任公司”,大模型可依据常见公司类型表述进行修正。这种端到端的语义增强OCR机制,使文档抽取系统具备了远超传统OCR方案的鲁棒性与泛化能力。
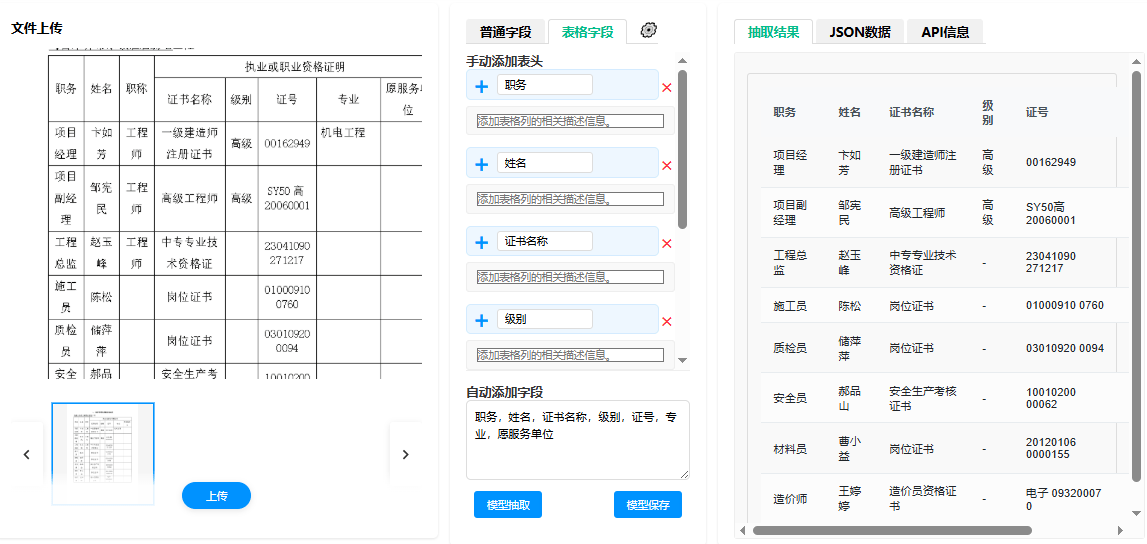
政务大厅场景应用:从信息提取到结构化处理全流程
中科逸视文档抽取系统已在政务大厅智能表单处理中实现多项落地应用,为窗口工作人员和办事群众带来显著的效率提升。
在“人工智能+”行动深入推进的宏观背景下,中科逸视文档抽取系统以OCR与大模型深度融合的技术架构,为政务大厅智能表单处理提供了从“看得见”到“读得懂”再到“抽得出”的一站式解决方案。该系统以高精度的多模态识别、无模板化的自适应解析、少样本的快速迁移能力、毫秒级的实时处理性能,有效破解了政务服务表单处理中效率低、误差高、适配难的痛点,成为推动政务服务从“自动化”迈向“智能化”的关键技术支撑。