专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
藏文,作为我国重要的少数民族文字,承载着千年的历史与智慧,广泛应用于西藏、青海、四川、甘肃、云南等地的文化、宗教、教育及行政领域。然而,由于其独特而复杂的结构,长期以来,实现高效准确的藏文识别成为了一项极具挑战性的任务。中科逸视(北京)科技有限公司凭借在AI核心算法及大模型融合技术领域的深厚积累,成功研发出高性能藏文OCR文字识别系统,为藏文信息的数字化处理开辟了新的道路。
技术原理:深度学习驱动的三重引擎
中科逸视的藏文识别技术并非传统OCR的简单升级,而是一个基于深度学习的系统性工程,主要包含数据准备、模型构建与端到端训练三个核心阶段。
1. 数据准备与预处理:基石工程
系统首先收集大量涵盖不同字体(乌金体、乌梅体等)、不同版式(古籍、现代印刷、手写)的藏文图像,并进行精细的数据标注。随后对图像进行灰度化、二值化、去噪、倾斜校正等标准化操作,并通过行切分和字切分将文本行与字符逐一分离,为模型训练做准备。
2. 模型架构:CNN+RNN的黄金组合
中科逸视的藏文识别模型主要基于卷积神经网络(CNN) 和循环神经网络(RNN) 的结合,并采用连接主义时序分类(CTC) 或注意力机制(Attention) 作为解码器。
3. 端到端训练
使用标注好的数据对构建好的模型进行端到端的训练,通过反向传播算法不断调整网络参数,并采用数据增强(旋转、缩放、添加噪声)、Dropout、学习率衰减等技巧防止过拟合。
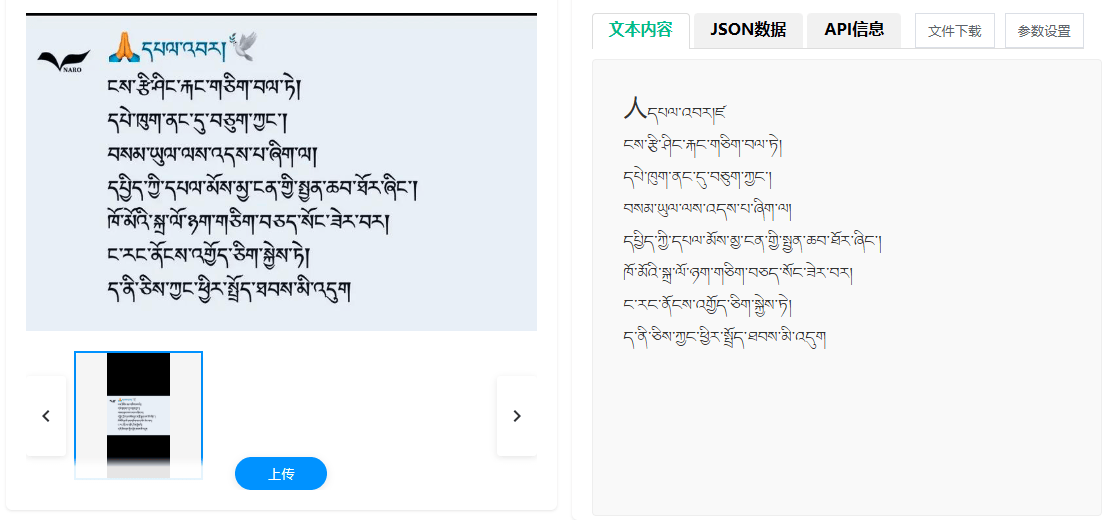
功能特点:精准、高效、灵活
中科逸视的藏文识别技术在性能上展现了显著优势,满足了实际应用中的多样化需求:
应用领域:从古籍保护到现代政务的全场景赋能
中科逸视藏文识别技术已广泛应用于多个领域:
中科逸视藏文识别技术,通过将前沿人工智能技术与深厚的藏语文化底蕴相结合,让古老的文字在数字时代焕发出新的生机与活力。未来,随着技术的持续迭代与应用场景的不断拓展,我们有理由相信,这项技术将在铸牢中华民族共同体意识、促进各民族交往交流交融中发挥更加重要的作用。