专注AI算法和大模型融合技术研发
-
商务合作
- 邮箱:easing@easingvision.com
- 手机:18600524535
- 电话:010-69992918
- Q Q:2175715190 点击交谈
- 地址:北京市龙发大街1号院3号楼4层
Copyright © 中科逸视(北京)科技有限公司 版权所有-备案号:京ICP备19041319号-2
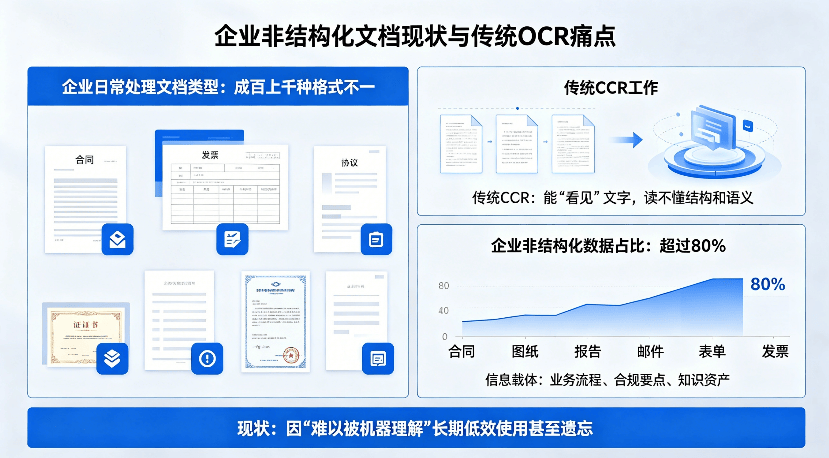
合同、发票、报告、协议、证书……企业每天都在处理成百上千种格式不一的文档,而其中真正有用的信息,往往只是寥寥数项。传统OCR虽然能“看见”文字,却读不懂结构和语义。企业超过80%的数据以非结构化形式存在,涵盖合同、图纸、报告、邮件、表单、发票等文档类型,这些承载着业务流程、合规要点与知识资产的信息载体,却因“难以被机器理解”而被长期低效使用甚至遗忘。
中科逸视通过其核心的智能文档抽取技术,成功跨越了从“数字化”到“智能化”的鸿沟,为金融、政务、物流等行业提供了高效的解决方案。
技术原理:从“像素识别”到“语义理解”的跃迁
文档抽取技术并非单一算法的堆砌,而是一套融合了计算机视觉、自然语言处理(NLP)和深度学习架构的系统工程。其核心逻辑可以概括为“感知 - 理解 - 重构”的闭环。
1. 高精度版面分析与布局识别
传统的OCR往往按行或按块机械地切割图像,容易丢失文档的整体结构信息。文档抽取采用基于Transformer架构的视觉编码器,结合图神经网络,能够精准识别文档中的标题、段落、表格、列表、印章等元素的边界框。
2. 端到端的深度学习识别引擎
在内容识别阶段,系统摒弃了传统OCR中“预处理+分割+识别+后处理”的串行流水线,转而采用端到端的训练模式。
3. 语义逻辑校验
这是文档抽取技术的“大脑”。识别出的文本不仅仅是字符流,而是带有语义标签的数据对象。
相对传统OCR的技术优势
传统OCR的核心能力是“识别文字”——从图像中提取字符。然而,它在面对跨页表格、图表解读、逻辑结构理解时就显得力不从心。文档抽取技术实现了对传统OCR的全面超越,主要体现在以下四个维度:
1. 零样本启动,无需标注训练
传统OCR+正则表达式的方案依赖大量模板配置与规则编写。文档抽取则实现了零样本启动——用户无需提供标注样本进行训练,只需配置想提取的字段名,系统即可自动理解并精准抽取。依托自研的垂直领域语义模型,系统基于海量基础数据完成预训练,具备极强的泛化能力,开箱即用即可达到精准的抽取效果。
2. 深度语义理解,而非浅层字符识别
传统OCR只能提取“文本字符串”,无法理解文档的“版面逻辑”和“语义关系”。文档抽取系统能够理解文档的上下文和深层含义,精准识别“应付金额”“合计”“总价款”等同义表述,并理解跨段落关联和隐含信息。
3. 复杂结构精准解析
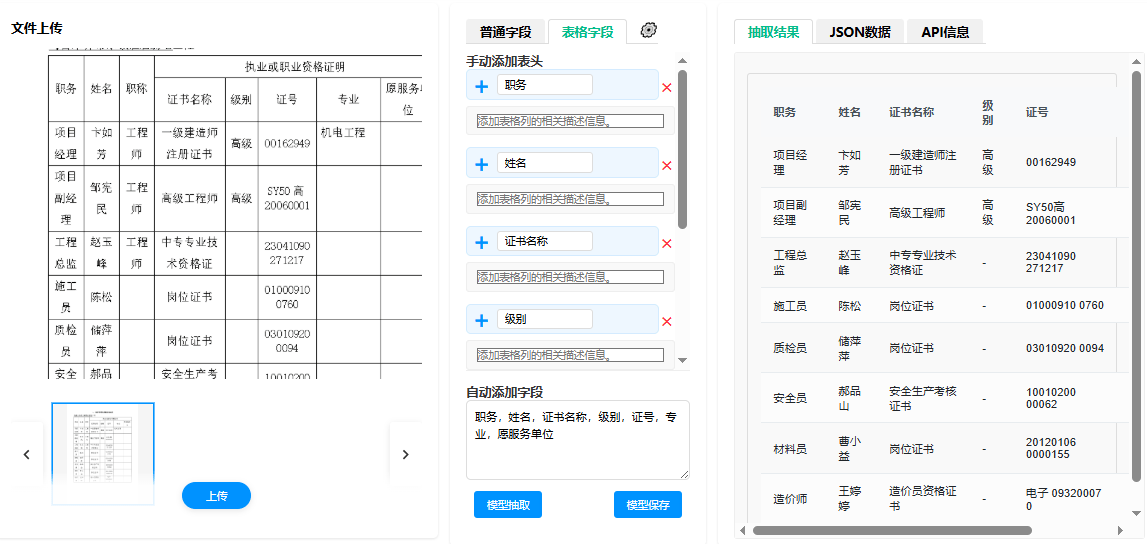
传统OCR在跨页表格、合并单元格、多栏排版等复杂场景下频繁出错。系统通过高精度版面分析,能够精准解析无边框、多栏、跨页、合并单元格等复杂表格,并还原其逻辑结构。系统具备自动跨页结构对齐能力,智能合并分页的表格表头与数据区,保证上下文连续性。
4. 多模态文档处理,图文并读
传统OCR只能处理纯文本,面对图文混排的复杂文档束手无策。文档抽取通过多模态技术实现“图文共读”,能识别扫描件、手写体、双层PDF等多种类型的文档内容,精准提取跨页表格、合并单元格、密集表格、手写字符及公式。
文档抽取技术核心应用领域
1. 金融科技
2. 政务服务
3. 物流与供应链
4. 法律与合规
中科逸视的文档抽取技术,本质上是一个以语义理解为核心的智能文档处理系统。它通过将高精度OCR、版面分析、多模态融合与大模型推理深度整合,实现了从“看见文字”到“理解文档”的质的飞跃。在当前“人工智能+”的政策背景下,这项技术能够帮助企业将海量非结构化文档转化为可操作、可查询、可推理的结构化数据资产,为各行各业的数字化转型提供坚实的技术底座。